Security is the One AI Workload I Won't Token-Optimise
 Veli-Matti Vanamo
Veli-Matti Vanamo
April 27, 2026
13 minutes to read
What a week.
Off the back of my 45-minute Microsoft AI Tour session, I spent time walking people through Insight’s AI Agents and a couple of the enterprise apps I’ve built and now manage using an Agentic SDLC. One question kept coming up about a particular skill I’d demonstrated, the Security Audit. A few people asked, very reasonably, what does this actually cost to run against a real project.
I didn’t have a good answer in the moment, so I went home and ran the experiment.
This post is the answer, plus a couple of things I learned about token economics along the way that I think every CTO, CFO, and engineering leader is about to need to think about.
First, the housekeeping. I evolved this skill from v1.0.5 into v2.0.6 by adding more scanners and broader framework coverage, then packaged it up and put it on GitHub: velimattiv/claude-security-audit. MIT licensed. It’s an amalgamation of multiple open-source scanners, methodologies, and frameworks (semgrep, gitleaks, trivy, osv-scanner, hadolint, plus OWASP ASVS, API Top 10, LLM Top 10, LINDDUN, STRIDE, and CWE tagging on every finding), wired together so a single Claude Code session can run a polyglot security audit across a real codebase and emit a SARIF report, a CycloneDX SBOM, and a structured findings blackboard. You’re welcome to fork it, file issues, or just lift the bits that look useful. I’m not claiming this to be the best, it’s just one that I put together for me and my projects. I expect these things to move fast, and this little skill will no doubt be superseded by something better in weeks.
Now to the experiment.
The $189 audit
I picked three of my own apps. All of them are internal Insight tools deployed behind VNets, NSGs, Front Door with WAF, and Entra-bound auth. None of them are sitting on the open internet. The three projects:
| Project | LOC (code) | Wall-time | Indicative cost (AUD) |
|---|---|---|---|
| Project A (Next.js 16 web app) | ~169k | 1h 25m | ~$104 |
| Project B (Python services + Vue UI + dbt pipeline) | ~144k | 51m | ~$47 |
| Project C (Nuxt 4 monolith) | ~200k | 39m | ~$38 |
| Total | ~513k | 2h 56m, run concurrently | ~$189 |
A few caveats on those numbers, because I’d rather be useful than dramatic.
The cost is indicative, not exact. I ran this on a Claude Max-20 plan using about $310 AUD of expiring extra credits, since I’d already exhausted my 5-hour token window for the day. The split across projects is a heuristic based on wall-time and partition depth, not a console export. Enterprise consumption pricing will land somewhere different, possibly higher per project, possibly lower depending on cache hit rate. I’ll get to find out next quarter when our projects move to consumption billing on both Claude Enterprise and GitHub Copilot. More on that in a minute.
The wall-time figures don’t track linearly with lines of code. The largest codebase ran the fastest, because runtime tracks attack-surface count and partition risk depth, not raw line count. So I wouldn’t recommend trying to predict cost from LOC alone for your own projects.
I deliberately used Opus 4.7 with the 1M context window in xhigh effort mode. This is the most capable model available for a job like this today, and as I’ll get to, I think security work is the wrong place to economise on capability or token optimise for context.
What it found, and the part where I stay grounded
Across the three projects the audit produced 853 raw findings. Of those, 41 were tagged CRITICAL and 105 HIGH. The skill also records the level of confidence (565 came back tagged CONFIRMED) and notes which findings were unique to it versus things the underlying scanners or my prior Copilot and Claude reviews had already caught. More than 500 findings were unique to this run.
Now the real talk.
I don’t believe most of those findings are exploitable in production. The model sees the code; it doesn’t see the WAF rules, the NSG topology, the Entra conditional access policies, or the fact that an app is only reachable from inside a specific VNet. Every one of these projects has those layers in front of it. A security professional triaging this report would discount a lot of findings the moment they put each one in operating context. Some categories are more reliable than others. Hardcoded secrets in DEV-only .env files, GitHub Actions shell injection patterns, JWT validation bugs, raw HMAC stored as if it were a hash, IaC misconfigurations, LLM concerns like prompt injection and unbounded consumption: those are concrete and don’t depend on perimeter context. Auth flows, BOLA scenarios, missing rate limits, those are exactly the ones that shift in significance once you add the infrastructure controls back in.
What surprised me wasn’t the headline numbers. It was that the audit surfaced things my earlier reviews didn’t, and my earlier reviews had surfaced things the audit didn’t. I’d previously run Copilot/Claude security review, two rounds of BMAD general adversarial review per PR, and the v1 of this very skill. Each of those produced its own list. Each one missed things the others caught. That’s a defence-in-depth lesson about review tooling itself, not just about runtime security architecture. Different lenses have different blind spots, and using multiple of them is cheaper than it has ever been.
The headline number doesn’t tell you which findings sit where on that spectrum; the per-finding methodology tagging (CWE, ASVS, API Top 10, LLM Top 10, LINDDUN, STRIDE) does. The value of the audit, for me, isn’t a parade of five-alarm fires. It’s having those prompts in front of me at all, early in the SDLC, on apps I built myself, while I’m the one still holding the context.
Token economics, no longer a personal budgeting problem
Here’s the bit I think is going to matter most over the next twelve months.
When I framed the $189 as “expiring credits on my personal Max plan”, that’s only the framing for one more quarter. As of February 2026, Anthropic moved Claude Enterprise off the flat ~$200-per-seat-with-bundled-tokens model, to $20 per seat plus standard API rates for every token your team consumes in chat, Claude Code, or Cowork. The Register reports that this could triple costs for heavy users compared to the previous structure. On April 23 of this week, Microsoft announced that GitHub Copilot is moving to token-based billing on June 1, citing weekly Copilot operating costs nearly doubling since January. The Insight projects I run are moving to Claude Enterprise this week, and to consumption-billed GitHub Copilot from June 1. So in roughly five weeks I’ll be operating on real consumption billing for the same kind of work I’ve been doing on a flat-fee plan.
This is the conversation every CTO and CFO is about to be in. It isn’t a hobbyist’s curiosity. It’s a budgeting discipline.
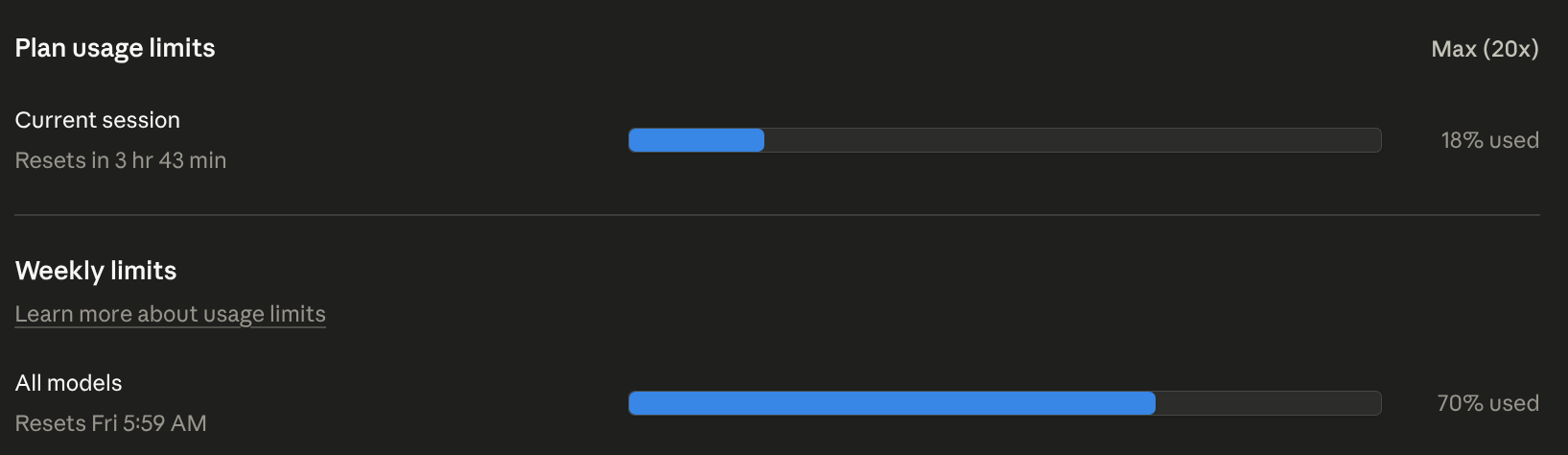 The Max (20x) plan, Anthropic’s top tier, viewed Monday midday. 70% of this week’s allocation already gone, accumulated across Fri-Sat-Sun-Mon work: project coding, the audit tool development itself, and the audit cycle that produced this post. Resets Friday morning.
The Max (20x) plan, Anthropic’s top tier, viewed Monday midday. 70% of this week’s allocation already gone, accumulated across Fri-Sat-Sun-Mon work: project coding, the audit tool development itself, and the audit cycle that produced this post. Resets Friday morning.
We’re going to have to learn when to optimise tokens, models, and context, and when not to, the same way we learned to manage cloud spend when we moved off CapEx. There will be workloads where you absolutely should optimise: prompt caching, context trimming, smaller models for routine work, careful agent budgets. There will be workloads where you shouldn’t, where the value of the output dwarfs the token cost.
For me, security is one of those.
Not because every finding is a five-alarm fire. Most of mine clearly aren’t. The first reason I won’t optimise tokens on a security audit is the learning loop. Running this skill on my own apps, often, with the most capable model available, makes me a better builder. I see the patterns. I notice my own habits. I get better at the next thing I write. That’s worth more to me, and I’d argue to my employer, than the sticker price of the audit.
The second reason is the part I want to be loud about. Two weeks ago Claude Mythos demonstrated AI’s ability to chain four to six vulnerabilities into a working exploit autonomously. That changes the maths on what counts as worth fixing. In the past I’d probably have brushed off many of the medium and low findings as too low to exploit individually and moved on. That shortcut doesn’t survive the Mythos era. A single LOW finding might be fine on its own; chained with three siblings, it isn’t.
So after the audit, I built a Security Epic for each project and worked through every CRITICAL, every HIGH, every MEDIUM, and roughly a third of the LOWs. Not because each one is a five-alarm fire, but because with AI engineering I can address them all in a reasonable timeframe. If I can, I will.
The audit run itself came to about $189 across the three projects. Working through every CRITICAL and HIGH on the resulting Security Epics took the total credit spend to A$312, and at that point I’d run out of tokens. The third project’s remediation is queued for next week. Three audits, two remediations finished, one waiting. That’s the lived reality of doing this kind of work at the edge of even the top-tier subscription.
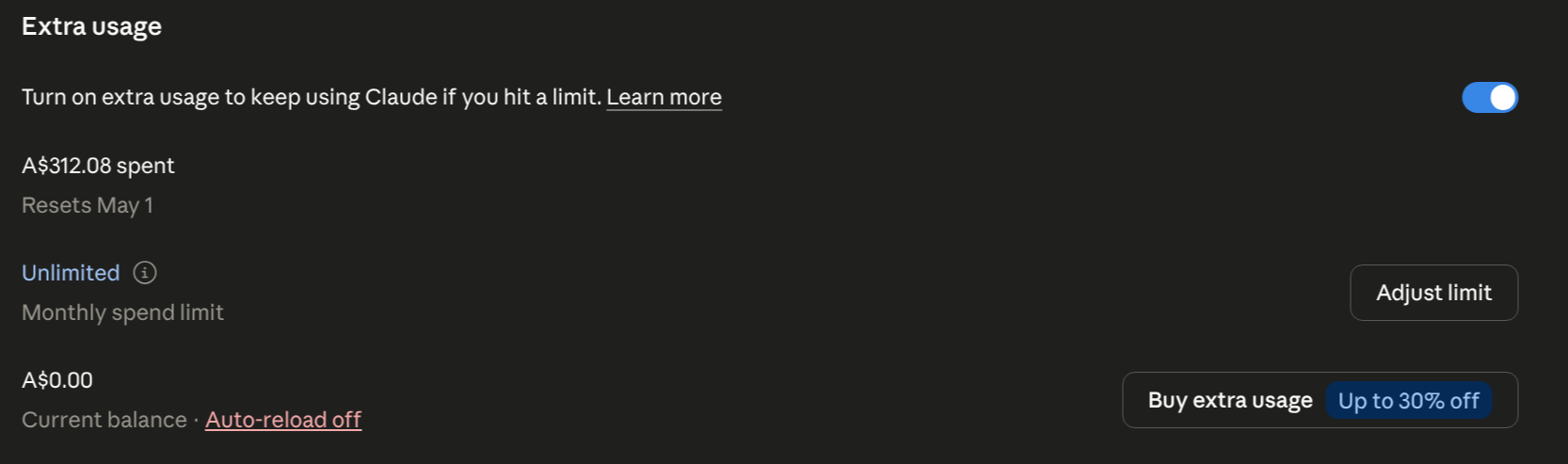 A$312.08 across the cycle: three audits plus critical/high remediation on two of them. The third is queued for next week. I ran out of tokens before I could finish.
A$312.08 across the cycle: three audits plus critical/high remediation on two of them. The third is queued for next week. I ran out of tokens before I could finish.
That’s also why I’m not waiting until next quarter to run this again. I’m running it every second week across every active project right now, and I’m working toward a steadier rhythm: delta mode after each sprint, a full audit every third or fourth. I haven’t settled on the right cadence yet. I’ll experiment my way there.
A two-week, $15k-to-$30k external pentest engagement still has its place. I’m not pretending this replaces it. But the cost of doing this kind of analysis has dropped far enough that I can do it on myself before anyone else has to look at the code, and that changes the shape of the SDLC for me as a non-security-specialist CTO.
Prepare, don’t defer
Mythos-class models don’t make this kind of audit cheaper. They make the audit more important and the deferral more expensive. Token consumption is going to keep climbing as the models get more capable, consumption billing is landing for everyone in the next quarter, and every week I keep building with AI engineering there is more code that needs auditing. The compound is heading the wrong way.
So the choice between “spend tokens cleaning this up now, while I still have a 1M Opus budget I can stretch with extra credits” and “spend much more later, plus whatever cost a chained exploit lands on us” isn’t really a choice for me. Every MEDIUM and LOW I leave in the codebase today is a candidate link in a chain a future model will trivially compose. The cheapest moment to fix it is now, with the model I have today.
This is what I mean about not deferring. It isn’t “wait until the budget catches up”. It’s “prepare and deal with now”. The token economics will get harder from here, not easier.
What’s next
I’m currently working on a GitHub Copilot agent version of this skill so my team can run it inside Copilot’s sandbox the same way I run it inside Claude Code today. I’m hitting a few execution-time limits in the sandbox, but I enjoy figuring this stuff out and I’ll get there. Open issues welcome.
Hope everyone can shift left too with this. I’m sure there are much better security audit skills out there, but this is just one example that worked for me, compiled off the back of great work others have done. I made my collection available for everyone to reuse, contribute, and add onto. Try it on a project you stopped looking at six months ago. That’s where mine surfaced the things I actually wanted to see.
From hype. To how.